In der Terminologie der TreeDB wird eine Datenbank als Domain bezeichnet. TreeDB unterstützt beliebig viele unabhängige Domains. Eine Domain beinhaltet jegliche Art von Daten, die notwendig sind, um eine Domain (=Datenbank) darstellen zu können, z.B. Datenstrukturen, Daten, spezifischen Programmcode etc.
 Als Veranschaulichung folgt eine Erläuterung des konzeptionellen Aufbaus der TreeDB anhand einer Zoo-Datenbank, die einige Tiere des Tiergarten Schönbrunns beinhaltet. Grundstruktur einer Domain ist ein gerichteter Baum mit den entsprechenden Knoten und Blättern. Der Aufbau eines Baumes entspricht einem vordefinierten Referenzbaum oder einem Regelwerk. Im Falle der Zoo-Datenbank leitet sich der Baum aus der taxonomischen Hierarchie der einzelnen Spezies ab. Als Referenz für den Import einer Spezies dient das ITIS (Integrated Taxonomic Information System).
Als Veranschaulichung folgt eine Erläuterung des konzeptionellen Aufbaus der TreeDB anhand einer Zoo-Datenbank, die einige Tiere des Tiergarten Schönbrunns beinhaltet. Grundstruktur einer Domain ist ein gerichteter Baum mit den entsprechenden Knoten und Blättern. Der Aufbau eines Baumes entspricht einem vordefinierten Referenzbaum oder einem Regelwerk. Im Falle der Zoo-Datenbank leitet sich der Baum aus der taxonomischen Hierarchie der einzelnen Spezies ab. Als Referenz für den Import einer Spezies dient das ITIS (Integrated Taxonomic Information System).
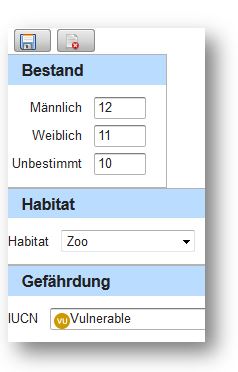
Jeder Knoten oder jedes Blatt eines Baumes entspricht einem bestimmten Datentyp, der die Art, die Organisation und die Darstellung der Daten beschreibt. In unserem Beispiel wird die Anzahl der Tiere nach Geschlecht, Gefährdungsstatus und weiteren Daten pro Spezies gespeichert. Diese Daten sind mit einer HTML-Vorlage verknüpft, die wahlweise eine Template-Engine wie FreeMarker, Velocity oder PHP in Kombination mit Makros einbindet, um die Substitution der Daten zu vereinfachen. In der Zoo-Datenbank kommt der vordefinierte Datentyp WIKI zum Einsatz, der einen HTML-Editor und eine Bildverwaltung inkludiert. Alternativ kann ein Java-BeanShell- Skript oder Java-Code zur Darstellung der Daten eingebunden werden.